Here's a quick thought exercise: I'm going to describe a type of player in three or four words and think of the first player who comes to mind who fits that description.
Pass-first point guard... Maybe someone like Chris Paul or Rajon Rondo?
Catch-and-shoot wing... I'm going with Klay Thompson or J.J. Redick.
Rim-running big... DeAndre Jordan feels about right.
Let's add a wrinkle - is Chris Paul's playing style more like Rajon Rondo or Steph Curry? I'm not sure if it's surprising or not, but by any subset of their statistics and tendency measures, Paul's game is more like Curry's than Rondo's.
Something I'm interested in developing is a way to characterize player roles. The 2K series has started adding these sort of roles for players, like 'Interior defender' for someone like Bismack Biyombo or 'All-around wing superstar' for LeBron James. But, after a certain point, calling a player an 'All-around superstar' doesn't exactly differentiate them from other players.
This is going to be a feeling out process for developing this process, testing it on point guards and their play from 2015-2016. Essentially, the idea is that I'll take a large swath of tendency measures (from nbaminer.com), stuff like usage from different zones, assist tendencies, pick-and-roll usage, and so on. I threw out point guards who played less than 50 games and less than 15 minutes a game, and only consider offensive statistics for now.
The first approach I use is something called k-means clustering. It's a really simple sort of algorithm to understand. From the data you have, you first try to estimate the maximum number of clusters that are significantly dissimilar from one another with some simple statistical calculations. Then, the algorithm guesses a first grouping and updates itself repeatedly until the groups aren't any better separated. One thing that's necessary for this process to work efficiently is to reduce the number of variables that are highly correlated with one another. After selecting for the most needed variables, it's possible to isolate four distinct groups of point guards:

Pass-first point guard... Maybe someone like Chris Paul or Rajon Rondo?
Catch-and-shoot wing... I'm going with Klay Thompson or J.J. Redick.
Rim-running big... DeAndre Jordan feels about right.
Let's add a wrinkle - is Chris Paul's playing style more like Rajon Rondo or Steph Curry? I'm not sure if it's surprising or not, but by any subset of their statistics and tendency measures, Paul's game is more like Curry's than Rondo's.
Something I'm interested in developing is a way to characterize player roles. The 2K series has started adding these sort of roles for players, like 'Interior defender' for someone like Bismack Biyombo or 'All-around wing superstar' for LeBron James. But, after a certain point, calling a player an 'All-around superstar' doesn't exactly differentiate them from other players.
This is going to be a feeling out process for developing this process, testing it on point guards and their play from 2015-2016. Essentially, the idea is that I'll take a large swath of tendency measures (from nbaminer.com), stuff like usage from different zones, assist tendencies, pick-and-roll usage, and so on. I threw out point guards who played less than 50 games and less than 15 minutes a game, and only consider offensive statistics for now.
The first approach I use is something called k-means clustering. It's a really simple sort of algorithm to understand. From the data you have, you first try to estimate the maximum number of clusters that are significantly dissimilar from one another with some simple statistical calculations. Then, the algorithm guesses a first grouping and updates itself repeatedly until the groups aren't any better separated. One thing that's necessary for this process to work efficiently is to reduce the number of variables that are highly correlated with one another. After selecting for the most needed variables, it's possible to isolate four distinct groups of point guards:
- Pick-and-Roll Generals: speedy points that have high mid-range and paint usage, but aren't great overall scorers.
- Spot-Up Shooters: shooting guards who guard the opposing team's point. They're used as floor spacers and ball-movers on teams with high usage wings.
- Shot Creators: the best of the best, the offensive do-it-all point guards who can score, facilitate, and spot-up, if need be.
- Score-First Drivers: point guards who try to get to the rim on every possession, regardless of the impact on their team.
Here's a list of some representative players in each of the four groups, with an approximate guide of where they're most likely to operate.

But what's more interesting, at least to me, is how these groups compare with one another. The heat map below gives us an idea how these groups separated. The score-first drivers and shot creators are differentiated entirely by the red cluster of variables (I know the heat map isn't red, but look at the tree graph, that's red) to the left - all of which are facilitation or shooting stats. Spot-up shooters have really high usage numbers above the break or beyond 24 feet. Pick-and-roll generals run around a lot (high distance per 36 minutes) and look to facilitate when inside the paint.
 There's some considerations to make though. Let's revisit the toy example from the beginning - compare Steph Curry and Chris Paul, both of whom the k-means clustering identified as shot creators. I'm sure that anyone would say that, to the naked eye, Paul's shot creation (in 2015-2016) was pretty different than Steph's. Paul's more of a pure point guard, someone whose first instinct is to make a play for Blake, whereas Steph's first instinct is to score, however possible. An easy fix is to ask the k-means algorithm to find distinguish all the point guards into more groups. However, by increasing the number of groups, the algorithm starts to include Steph in groups with players like Steve Blake and Pablo Prigioni. That's not really right either.
There's some considerations to make though. Let's revisit the toy example from the beginning - compare Steph Curry and Chris Paul, both of whom the k-means clustering identified as shot creators. I'm sure that anyone would say that, to the naked eye, Paul's shot creation (in 2015-2016) was pretty different than Steph's. Paul's more of a pure point guard, someone whose first instinct is to make a play for Blake, whereas Steph's first instinct is to score, however possible. An easy fix is to ask the k-means algorithm to find distinguish all the point guards into more groups. However, by increasing the number of groups, the algorithm starts to include Steph in groups with players like Steve Blake and Pablo Prigioni. That's not really right either.
So, I tried a more complex algorithm, fancily named Gaussian mixture modeling. It's the same type of deal - the underlying assumption is that, in your large swath of data, there's hidden underlying groups. Mixture modeling is a method of extracting those groups. This time, the model spits out 5 different groups, and they're pretty interesting:



So, I tried a more complex algorithm, fancily named Gaussian mixture modeling. It's the same type of deal - the underlying assumption is that, in your large swath of data, there's hidden underlying groups. Mixture modeling is a method of extracting those groups. This time, the model spits out 5 different groups, and they're pretty interesting:
- Personal Shot Creators - gunners, invariant to efficiency.
- Finishers - players attuned to finding the rim at all costs.
- Chris Paul - he's literally a group by himself.
- Off-Ball Shooters - point guards who play off ball-dominant wings.
- Shaun Livingston - again, a distinct player in his own right.
Here's some representative players from each of these five groups:

So, how do these groups compare? Personal shot creators have medium usage and efficiency in all facets of the game - finishing, mid-range, three point, and facilitation. Finishers love using the interior, especially the restricted zone but do very little else on the floor. Off-ball shooters love the corners and mostly score their points off assists from their teammates. Chris Paul has total domination of passing statistics and mid-range usage and efficiency. Shaun Livingston is an anomaly; with the 2015-16 Warriors, he was used mainly to punish bench point guards in the post and his turnaround jumper from 12 to 16 feet was lethal.

This more complex algorithm solves some of the issues of distinguishing point guard unicorns. But it's still doesn't have the granularity that I'm searching for. For example, many of the classified off-ball shooters are actually bad shooters, like Austin Rivers, Garrett Temple, and Devin Harris, which may suggest that efficiency is downplayed in this algorithm. These same players were classified as drivers in the simpler, coarser k-means clustering.
But what's the moral of the story? Not much really, at least not right now. But so that you don't feel like you wasted ten minutes of your life, here's an easy-to-follow graph, but it doesn't really say much either. Most starting point guards are pick-and-roll heavy players or scoring point guards. But we need to figure out the impact of lineups of different point guards.
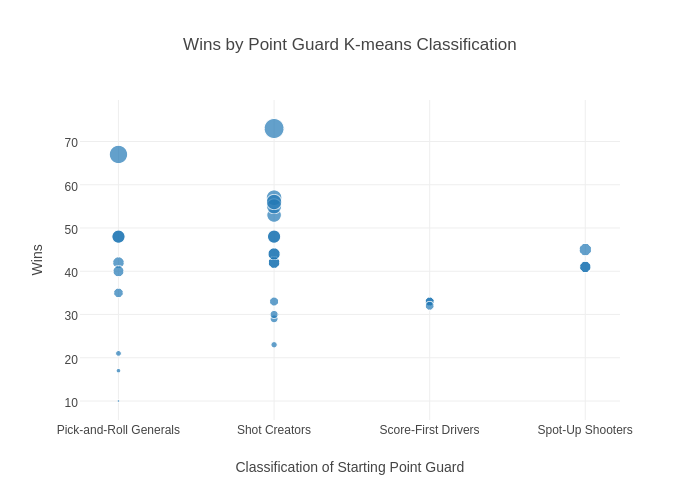
So here are my next steps: finalize a procedure to classify these point guards, employing some semi-parametric or non-parametric clustering techniques, and conduct some form of analysis of how lineups perform with different point guard styles. This starts to fall into the realm of causal inference, estimating the difference between two situations, both of which aren't necessarily observable. Answering questions like that can help elucidate how to identify complementary talent, especially after a team's found their cornerstones for the future. And, if you wanna listen to me stumble around this topic a little more, listen to Episode 20 of The Crevice, right down below.
So here are my next steps: finalize a procedure to classify these point guards, employing some semi-parametric or non-parametric clustering techniques, and conduct some form of analysis of how lineups perform with different point guard styles. This starts to fall into the realm of causal inference, estimating the difference between two situations, both of which aren't necessarily observable. Answering questions like that can help elucidate how to identify complementary talent, especially after a team's found their cornerstones for the future. And, if you wanna listen to me stumble around this topic a little more, listen to Episode 20 of The Crevice, right down below.
Comments
Post a Comment